Screenshots
| Version 1.3.0 | |

Click to view larger image
|
For the first time since SquidFire's inception, the main screen has received a major face lift. Now the total number
of rows as well as the name of the log file are listed directly from the main log list. This change will also make it
easier to add additional information in the future.
|
Click to view larger image
|
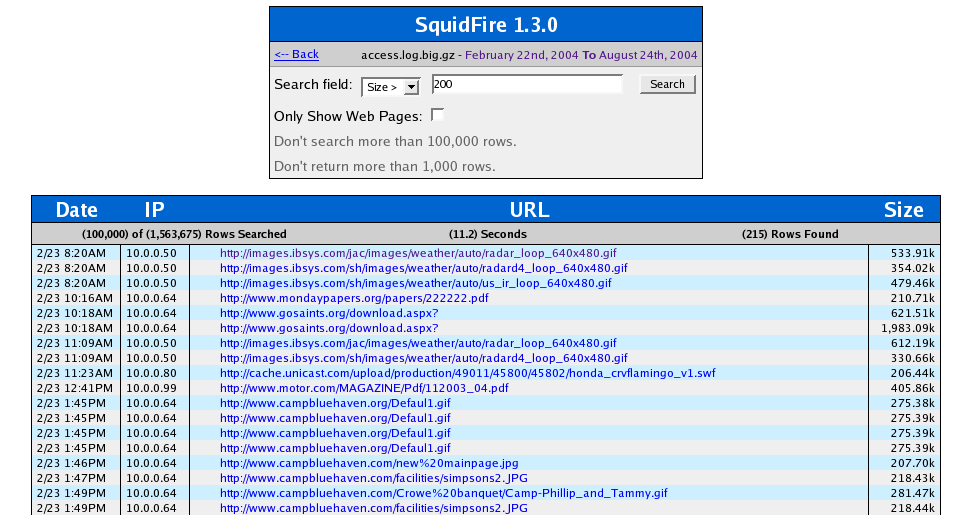
Size does matter, at least when it talking about squid logs. Now requests can be searched by size and the size
of each request is displayed by default in the results grid. Speaking of size, notice the number of rows in the
log file being searched. This specific search scanned 100,000 rows out of 1.5 million in 11.2 seconds. Much faster
than the previous version which use grep.
|

Click to view larger image
|
This is a pretty boring search, but notice how the results are listed. Actual web pages show up in bold and
left justified. Secondary requests such as images and javascript requests are indented. The type of request is
figured out by looking the mime type returned by the web server. However, there are a lot of broken servers out
there that don't return mime types at all so the script also trys to determine the file type by the extension if
it exists. A lot of work went into this feature to make it extremely accurate.
|

Click to view larger image
|
Same search as above except with the "Only Show Web Pages" option. Notice that 30,117 rows were searched this time
before the maximum of 1,000 results was reached. Without this option checked only 4,826 rows were scanned before the
max result limit was reached.
|

Click to view larger image
|
I left the best screen shot for last. This is a search through my largest test log file for the word "Mississippi".
My 2GHZ development box finishes this search in only 148 seconds, which I think is pretty good. First, this file is
compressed so it has to be uncompressed on the fly as its searched. The file is about 200mb uncompressed and has more
than 1.5 million rows of requests. This same box can simply read and parse this same file in 96 Seconds so there is
about 50 seconds of overhead doing the actual search as well as mime-type detection.
|